

こんにちは。完全自動化研究所の小佐井です。
SikuliXで日本語を扱う際のトラブルを解決する方法について解説します。
SikuliXでPythonを使って記述したとき、日本語を扱う際に文字化けしたり、すぐ「UnicodeDecodeError」や「UnicodeEncodeError」というエラーが発生しませんか?
この記事では、SikuliXの初心者が絶対困る文字コードについて解説します。
それでは、どうぞ!
(株)完全自動化研究所代表のこさいです。
1) ITエンジニア歴25年超。RPA開発歴8年超。
2) RPA関連の書籍を6冊出版。
3) RPAトレーニング動画を販売しています。
4) Power Automate Desktopフロー販売を行っています
5) ご質問・お仕事のご依頼はこちら!
Sikuliの日本語の文字化けに悩まない!【文字コードを攻略しよう】

文字コードの基本的な知識
まずは文字コードについての基本的な知識を解説します。
文字に割り当てられた「数値」の対応付けのことです。
以下の2つの概念が組み合わさって、コンピュータの文字は表現されています。
- 文字集合
- 符号化方式
1.文字集合
文字には日本語、英語、中国語など様々な文字が存在します。これらの文字から表現したい文字の集合体を定義します。これが文字集合です。ASCIIやJIS、Unicode(※1)などは文字集合です。
2.符号化方式
文字集合を運用しやすいように別のバイト列(数値)に変換する方式のことです。符号化方式は、複数の文字集合を組み合わせる、過去への互換性を保つ、などといった要件を達成します。EUC-JPやShift_JISはJIS系の文字集合を符号化する方式であり、UTF-8、UTF-16はUnicodeの符号化方式です。Unicodeを例に図で見ると図1のようになります。UTF-8もUTF-16も数値の振り方は違うものの、表現できる文字の種類は同じです。
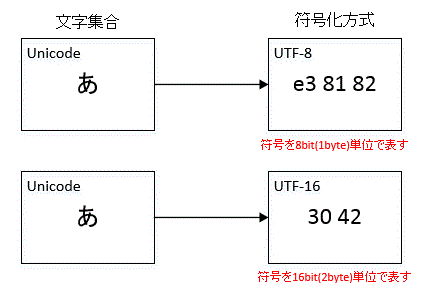
図1:文字集合と符合化方式
(※1)Unicodeは世界で使われるすべての文字を1つの文字集合で利用できるようにしようという考えで作られており、UniX、Windows、macOC、Javaなどで利用されている。
Pythonの文字列型には次の2つがあります。
- str型・・・純粋なバイトの列。
- Unicode型・・・Unicodeを表現可能な文字列型。
EncodeとDecode
- Encode…unicode型からstr型(UTF-8、Shift-JIS、EUC-JPなど)に変換すること。
- Decode…str型からunicode型に変換すること。符号化方式から文字集合に復帰させる。
暗黙的な文字列型の変換
pythonが「unicode型」と「str型」を自動的に変換する場合があります。「UnicodeDecodeError」、「UnicodeEncodeError」の大半はPythonの暗黙的な型変換によって発生しています。
1.自動的にDecodeされる場合
「unicode型」と「str型」を連結、比較など(str型→unicode型への自動変換)
2.自動的にEncodeされる場合
print文で標準出力・標準エラーに出力する場合など(unicode型→str型への自動変換)
Str型の確認
Str型を確認するためにリスト1を記述してください。
#type()を使うため。SikuliXではtype関数は文字入力のために使われている。
try:
import builtins
except ImportError:
import __builtin__ as builtins
str1 = "完全自動化研究所"
print builtins.type(str1)
print str1
popup(str1)リスト1 Str型の確認
文字列を定義するときに「”」で囲んだだけだとstr型(UTF-8)になります。リスト1を実行するとメッセージウィンドウには正しく出力されます(リスト2)。「<type’str’>」と出力されていることから、文字列str1の型は「Str型」であることがわかります。print文への出力はStr型ですから問題なく表示されたわけです。
しかし、popupはUnicode型であることを前提にしているので、文字化けが発生します(図2)。
<type'str'>
完全自動化研究所リスト2 リスト1実行後のメッセージウィンドウ
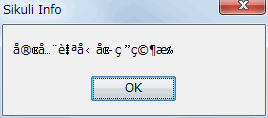
図2:文字化けしたポップアップ
Unicode型の確認
ソースコードを変えて実行してみましょう。popupはUnicode型であることを前提にしているので、str型(UTF-8)からUnicode型にDecodeしてあげれば、正しくpopupしてくれるはずです(リスト3)。
実行すると、12行目の「print str2」でエラーが起きました。print文はstr型で出力される決まりですので、Unicode型からstr型へ自動的に変換(Encode)されます。このときにエラーが起きています。
内容をみると「UnicodeEncodeError」です。「自動的にエンコーディングされる文字コードがasciiになっているので、日本語(正確にはUnicode)をEncodeできませんよ」というエラーですね。
#type()を使うため。SikuliXではtype関数は文字入力のために使われている。
try:
import builtins
except ImportError:
import __builtin__ as builtins
str1="完全自動化研究所"
str2=unicode(str1,"utf-8")
#以下でも同じ
#str2=str1.decode("utf-8")
print builtins.type(str2)
print str2
popup(str2)リスト3 Unicode型の確認
----------------------------------------------
【メッセージ】
----------------------------------------------
<type 'unicode'>
[error] script [ 無題 ] stopped with error in line 12
[error] UnicodeEncodeError ( 'ascii' codec can't encode characters in position 0-7: ordinal not in range(128) )リスト4 リスト3実行後のメッセージウィンドウ
デフォルトエンコーディングをUTF-8にする
あっちを立てれば、こっちが立たずという状態ですね。両方をうまくいかせるためにデフォルトでEncodeされる文字コードをasciiからUTF-8にしましょう。1行目から4行目までのプログラムを追加します(リスト5)。
実行するとメッセージウィンドウに「完全自動化研究所」と正しく表示されています(リスト6)。「sys.setdefaultencoding(‘utf-8’)」の文で、デフォルトでEncodeされる文字コードをUTF-8としているため、自動的にunicode型からstr型へEncodeされているわけです。ポップアップにも正しく表示されます(図3)。
import sys
reload(sys)
#デフォルトエンコーディングの文字コードをUTF-8にする
sys.setdefaultencoding('utf-8')
#type()を使うため。SikuliXではtype関数は文字入力のために使われている。
try:
import builtins
except ImportError:
import __builtin__ as builtins
str1="完全自動化研究所"
str2=unicode(str1,"utf-8")
#以下でも同じ
#str2=str1.decode("utf-8")
print builtins.type(str2)
print str2
popup(str2)
リスト5 デフォルトエンコーディングをUTF-8にする
<type'unicode'>
完全自動化研究所リスト6 リスト5実行後のメッセージウィンドウ
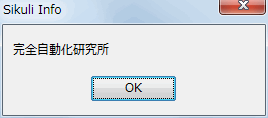
図3:正しく表示されたポップアップ
簡単にUnicode型を使う記述法
文字列を定義する際に頭に”u“を付けても、Unicode型として認識されるので、正しく表示されます。これをつかうとstr2でわざわざstr1をunicode型にDecodeする必要はありません。よって、以下のように書けばよいです。
str1 = u"完全自動化研究所"プログラムを整理します
SikuliXはPythonを使っていますから、Pythonの流儀に従います。PythonはUTF-8でソースコードを書くことが一般的ですので、ソースコードの冒頭に次のように書きます。このページには直接関係しませんが、ソースコードをライブラリ化するときには必要となりますので、必ず書くくせを付けておいたほうがいいですよ。
# coding: utf-8さて、これを踏まえて、すべてのソースコードを整理すると次のようになります。正しく動作しますね。
# coding: utf-8
import sys
reload(sys)
#デフォルトエンコーディングの文字コードをUTF-8にする
sys.setdefaultencoding('utf-8')
#type()を使うため。SikuliXではtype関数は文字入力のために使われている。
try:
import builtins
except ImportError:
import __builtin__ as builtins
str1=u"完全自動化研究所"
print builtins.type(str1)
print str1
popup(str1)
リスト7 整理したソースコード

